HPL is increasingly viewed as outdated and not representative of real applications. This can skew machine design and presents a conflict between the Top500 rankings and procurement in the best interest of users. The HPCG benchmark was recently proposed to augment HPL. HPGMG intends to be a more balanced, robust, and diverse benchmark that provides a better representation of a supercomputer's performance.
Why full multigid?
Since its introduction 40 years ago, full multigrid (FMG) has been the fastest approach to solving elliptic problems, with no viable competitors on the horizon. It is an asymptotically-exact direct solver that provides inexpensive metrics to check for correctness. Its computation and communication structure is similar to other fast algorithms such as FMM and FFT, which more applications seek to adopt as their legacy methods experience imperfect scaling. Solving a hard globally-coupled problem using the best known methods implicitly requires a well-engineered machine.
Why geometric (GMG) instead of algebraic (AMG)?
While geometric and algebraic multigrid have similar communication patterns in the solve, the setup cost for AMG is much higher and the setup implementation is much more complicated. Furthermore, use of assembled sparse matrices causes the local computation to be overwhelmingly limited by memory bandwidth. In order to represent algorithms that have higher intensity (more flops for each byte loaded into cache), it is necessary to avoid defining the fine-grid operator using an assembled sparse matrix. AMG could be used on coarse grids, but this would add significant implementation complexity without fundamentally changing the way the machine is exercised. The most interesting characteristic of assembled matrices is that the matrix entries are not reused (when operating on only one vector at a time), while vector entries are reused (if the ordering permits). This mix of reusable and non-reusable memory streams rewards high-quality cache and prefetch logic, but can be replicated in geometric multigrid using stored coefficients at quadrature points, see HPGMG-FE for further discussion. Finally, AMG is less mature than GMG in the sense that there are many open questions about coarsening algorithms and efficient implementation.
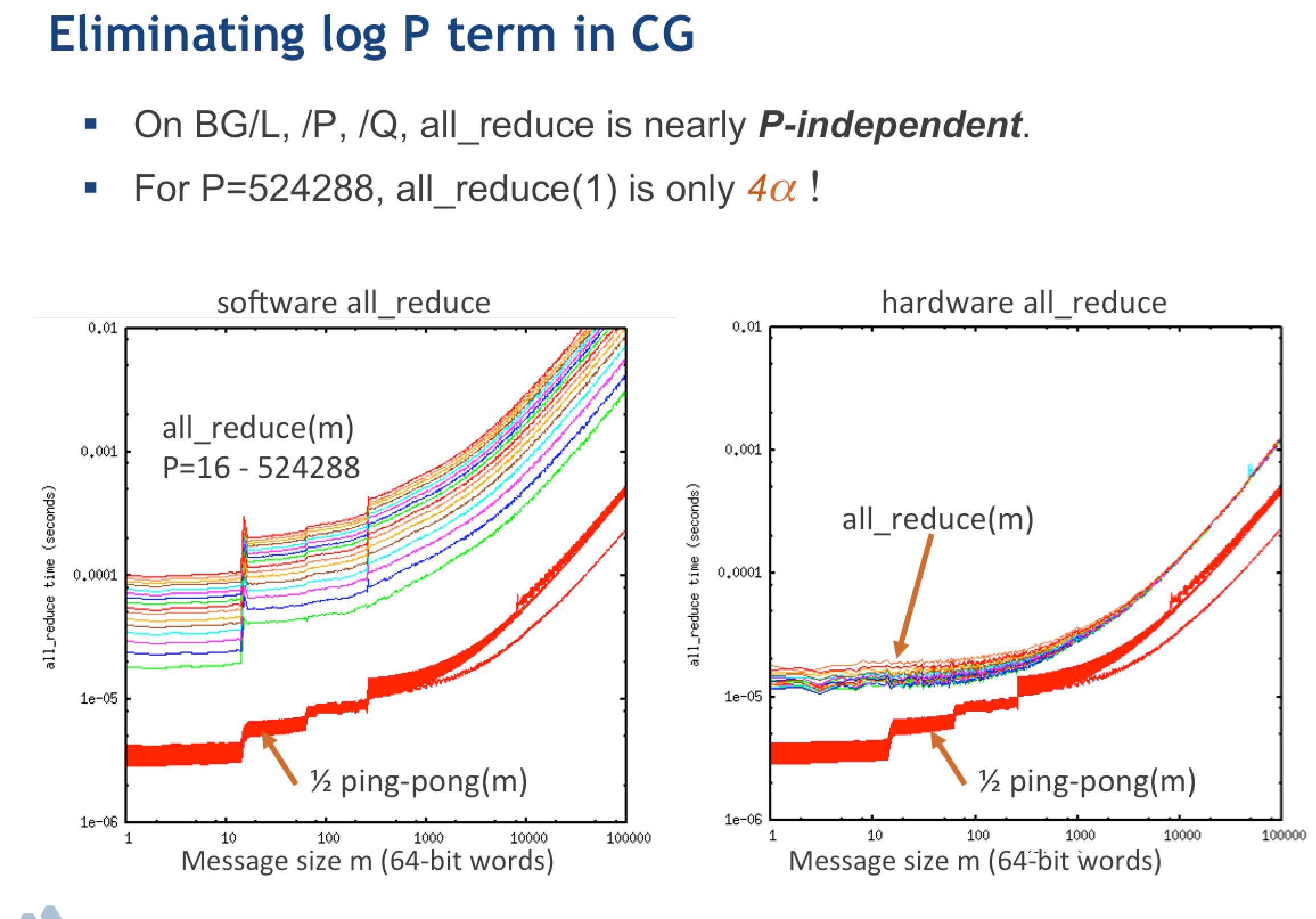
Why no reductions?
The coarse levels of a complete, distributed multigrid cycle is already a more challenging type of synchronization than the MPI_Allreduce in a Krylov method.
Any machine that can do FMG fast can also provide a fast MPI_Allreduce.
(Indeed MPI_Allreduce can be implemented as a tree reduced followed by tree broadcast, which can be described as a sort of degenerate V-cycle. A real V-cycle does strictly more computation and generally more communication.)
At least one current implementation of MPI_Allreduce has been shown to scale sub-logarithmically with constants orders of magnitude faster than an MG cycle.
For the problem classes considered, FMG is a direct method (converges in one iteration) and cannot benefit algorithmically from Krylov, so we have left it out.
There are ways to incorporate reductions in algorithmically essential ways if the community deems that to be necessary.
{kind=link}
Why not Gauss-Seidel?
The convergence of Gauss-Seidel depends on the ordering. A classical approach is to use coloring, but the memory access pattern for many colors is poor and multiple colors increase computational depth. Gauss-Seidel in lexical orderings can be optimized to approach the performance of sparse matrix-vector products (SpMV) on some hardware with a modest number of threads, but computational depth proportional to the diameter of the problem graph makes this impractical for extreme parallelism of PDE solvers. Parallelism and decent memory locality can be achieved with other orderings (see Adams 2001), but it is difficult to check that the implementation is sequentializable, i.e., (multiplicative) Gauss-Seidel rather than having some additive part.
Some multigrid packages (e.g., BoomerAMG) have advocated the use of block Jacobi with lexical Gauss-Seidel on subdomains. This was adopted by HPCG and can be a practical choice, but it requires legislation of the hardware unit upon which the algorithm must be multiplicative rather than additive. Is it a vector lane, a hardware thread, a core, NUMA node, socket, network device, etc? What about future architectures that break our usual perception, such as processing-in-memory? The performance of Gauss-Seidel on any unit of hardware is bounded above by the performace of Jacobi on that hardware (eliminating data dependencies while performing the same arithmetic is never slower) so there will be incetive for vendors to choose the smallest unit. For problems suitable for a benchmark (e.g., smooth coefficients), damped Jacobi convergence is similar to Gauss-Seidel. By using Chebyshev smoothers, our benchmark specification is independent of hardware scales and convergence is independent of the number of processes used (and hence could be made bitwise-reproducible). The implementation is also simpler because only operator application needs to be optimized.