We are proud to announce HPGMG-0.1, the first release of a new benchmark for HPC machines based on geometric multigrid methods.
Check out the v0.1 tag in the repository or download the tarball.
HPGMG contains a finite-volume and a finite-element implementation.
Both are full multigrid (FMG) methods using Chebyshev smoothers, thus have similar large-scale communication patterns, but the local computational kernels and memory/cache demands are different for each discretization.
Finite-volume performance results are available for several of today's top machines.
If you are interested in this effort, please subscribe to the HPGMG-Forum mailing list.
Kiviat diagrams
Although the relative performance of our implementations varies significantly between different architectures, performance data is available for Blue Gene/Q using HPM. Thanks to Ian Karlin and Bert Still (LLNL), we use kiviat diagrams to compare the current HPGMG implementations to other benchmarks and applications on the basis of:
- INT-IPC: integer (including load/store) instructions per cycle,
- FPU%: fraction of instructions that use the floating point unit,
- B/cycle: bytes per cycle transferred from DRAM, and
- GFLOPS: total gigaflops sustained by the application (rescaled).
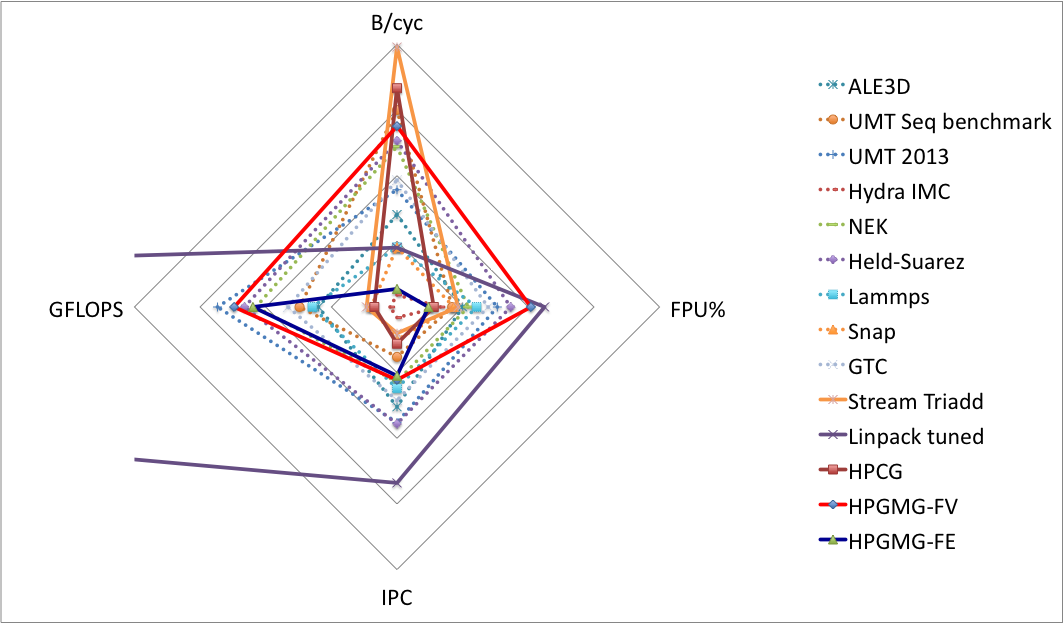
Note: the relative performance of HPGMG-FE is significantly higher on other architectures, we believe due to pessimal cache behavior on BG/Q. We are working on an implementation that will be less sensitive to the BG/Q cache.